
How to detect sarcasm detection with NLP
An overview of the research in a highly complex phenomenon


You’ve probably made this face when you’ve tried to know if someone is being sarcastic. It’s not easy to detect it for humans, how about machines?
Note: for the sake of brevity, this post will only consider sarcasm detection with tweets and using deep learning models.
Sarcasm detection is a very narrow research field in NLP, a specific case of sentiment analysis where instead of detecting a sentiment in the whole spectrum, the focus is on sarcasm. Therefore the task of this field is to detect if a given text is sarcastic or not.
The first problem we come across is that, unlike in sentiment analysis where the sentiment categories are very clearly defined (love objectively has a positive sentiment, hate a negative sentiment no matter who you ask or what language you speak), the borders of sarcasm aren’t that well defined. And it is crucial that before starting to detect it, to have a notion of what sarcasm is.
What is sarcasm?
The Oxford dictionary provides the following definition:
Sarcasm is the use of language that normally signifies the opposite in order to mock or convey contempt.
Some people could disagree about its purpose, but there is a convention in that people use positive words in order to convey a negative message. Of course, it varies through person to person and is highly dependent on the culture, gender and many other aspects. Americans and Indians for example, perceive sarcasm differently.
Moreover, someone being sarcastic doesn’t mean the other person perceiving it as the speaker intended. This subjectivity will have implications in the performance of DL models.
1. Data: Twitter datasets
Primarily, two Twitter datasets have been used to conduct research:
Riloff et al., 2013
Their dataset consists of automatically extracted tweets: 35k containing the hashtag #sarcasm and 140k random tweets.
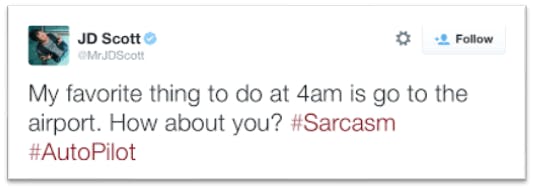
An example of the Riloff dataset
This dataset is large compared to the other datasets, yet very small compared to the datasets used in DL models. It is imbalanced, meaning there are more non-sarcastic tweets than sarcastic, which is realistic since sarcasm is very rare in our daily interactions and datasets should represent reality as best as they can. And regarding the type of sarcasm, this dataset captures intended sarcasm, this tweet is labelled as sarcastic because the author wants it to be, it doesn’t consider people’s perception.
Ptáček et al., 2014
Their dataset consists of manually annotated tweets: they annotated 7k tweets as sarcastic and added another 7k random ones.
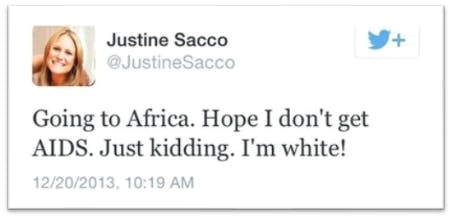
An example from the Ptáček dataset
This dataset is much smaller since manual annotation is more time intensive. These researchers also chose to make it balanced, augmenting sarcastic examples more than what is usual in order to help the model generalize better. And in this case, the tweets labelled as sarcastic are the ones the annotators perceive as sarcastic (perceived sarcasm), the intention of the author isn’t considered.
This tweet went viral in 2013, the woman wrote the tweet before getting on a plane and when she landed in the African country she was visiting, Twitter had exploded, she received many messages accusing her of all sorts of things, she even lost her job… When someone finally let her speak, she said she was being sarcastic and joking and she didn’t mean to offend anyone. But at that point, her intention was irrelevant.
2. Features
Historically, many layers of features have been added to the raw tweets:
- Cleaning: removing other hashtags, links, images.
- Lexical features: removing stopwords, tokenizing, BoW, POS tagging
- Pragmatic features: smileys/emojis, mentions
- Context incongruity: the context not being in agreement. Can be explicit and implicit
- User embeddings: stylometric and personality features. This embeddings encode a Twitter users’ information in a way that two similar users have a similar embedding. Because they tweet about the same topic, write with a similar style, or have comparable behavior patterns.
The idea of the user embeddings is that if there is a user in the training data with a certain personality, and they happen to make sarcastic tweets, then when we get new data and there is a new user that has a similar style and therefore similar embedding to the previous user, without looking at the new user’s tweet, we can predict if this user will be sarcastic or not. Just by looking at the similarity of the embeddings.
The last 2 features are fairly recent at the time of writing, and have replaced the purely linguistic and lexical features used in the early years of the research.
3. Models
There’s a myriad of DL models and combinations of architectures and it’s not the goal of this post to analyze models in depth.
Up until 2017, most models were Machine Learning models, logistic regression, SVM, and some attempts with CNNs.
Around 2017, LSTMs started to have traction and because of their sequential nature and easier handling of long-range dependencies, they took over the ML models. Attention models such as Transformers quickly replaced these too, and nowadays a combination of Transformers, dense networks and CRF layers are being used.
4. Analysis
Different papers have different evaluation methods, but in almost all cases, human evaluation is poor and the models’ evaluation even worse. Possible reasons may be the small amount of data and humans themselves not being able to detect sarcasm.
One of the major papers analysing the current stand of the research was from Oprea and Magdy, 2019 where they pose 3 questions they aim to answer:
- Is the user embedding predictive of the sarcastic nature of the tweet?
- What role do user embeddings play in Riloff vs. Ptacek datasets?
- What is the performance difference between the two datasets?
The first question, in other words, asks whether we can predict sarcasm just by knowing a user’s past behavior and personality, without looking at the tweet. Generalizing a bit, is sarcasm random or are there certain personality features that make someone more probable to be sarcastic?
And if so, what is their influence on the two datasets? Does knowing someone, their hobbies and interests, their personality, help us detect if they are being sarcastic?
And regarding performance, training models on these two datasets, where does the DL model perform better?
I encourage the readers to stop reading for a while and try to guess the answers and think of why, based on your intuition and what you’ve read so far.
This monkey is thinking hard about user embeddings and preventing you from seeing the answers right away, encouraging you to spend a minute thinking about them :)

Photo by Paolo Nicolello on Unsplash
The paper shows that indeed, users have a disposition to be sarcastic or not, based on their historical behavior. It seems natural to us that some people are more sarcastic than others, but this is the first time that someone publishes that yes, personality and sarcasm are correlated in tweets.
To answer the second question, user embeddings are good predictors in the Ptacek dataset, but not on the Riloff one. This implies that when detecting sarcasm on others, it helps to know them. But when detecting their intended sarcasm, adding user embeddings doesn’t seem to add any value.
Regarding the third question, DL models perform quite well on Riloff, but not on Ptacek. There might be many reasons for this, the balance/imbalance, the different type of sarcasm they capture, but in my honest opinion, at this point it’s just about the size (35k sarcastic tweets in Riloff, 7k in Ptacek). I believe the model has better results on Riloff simply because there are more tweets to train from. It would be very interesting to see the differences if the datasets had the same size.
This paper was also the first to officially say that due to the lack of coherence in results between Riloff and Ptacek, they conclude that these datasets are not equivalent, they capture distinct phenomena, namely, intended and perceived sarcasm.
The implications from this paper are huge and I expect to see the impact on the papers published in 2020 onwards.
5. Current stand and future research
Currently, generally speaking, people are using mostly text data, from Twitter and Reddit generally but also from other discussion forum posts.
As for the features, they use some lexical features, contextual embeddings for words (BERT), and user embeddings.
Every month there are new published models, usually a combination of Transformers with some dense layers.
Some errors that are common nowadays are:
- False negatives: sarcastic tweets not being detected by the model, most probably because they are very specific to a certain situation or culture and they require a high level of world knowledge that DL models don’t have. The most effective sarcasm is the one tailored specifically to the person, situation and relationship between the speakers.
- Sarcastic tweets written in a very polite way are undetected. Sometimes people use politeness as a way of being sarcastic, highly formal words that don’t match the casual conversation. Complimenting someone in a very formal way is a common way of being sarcastic.
Future research
As future research, I would hope to see more work done on datasets, bigger, more complete, more diverse datasets instead of ever-growing complex DL models. A model is as good as its data and the datasets used until now have their biases and limitations.
There has actually been a new dataset published at the end of 2019, iSarcasm by Oprea and Magdy, where users contribute their own sarcastic tweets and include an explanation as to why it’s sarcastic, as well as some metadata about them. Unfortunately it’s not very big (around 1k tweets) but it’s a small step in the right direction, in my opinion.
One of the biggest challenges of DL seems to be adding world knowledge to models, which would speed up training and help tremendously with generalization and bias. But the question is how. As of now, there is no answer.
And lastly, some people are going beyond text and using multimodal sarcasm detection with images and audio too, training the models on data from TV shows like The Big Bang Theory and Friends. It’s still in the early stages but considering the multimodality of sarcasm, it looks promising. Many times the sarcasm is not in the text, but in the intonation or face expression.
That’s the overview of sarcasm detection as of early 2020, I hope it’s informative enough so that anyone with a minimum machine learning knowledge can understand and get up to date with the research.
You can find notes of the majority of papers published in sarcasm detection in my Github as well as slides from my presentations. I’ve put links to the specific papers I’ve referenced directly in the post.
I’d love to discuss ideas and approaches to detect sarcasm, or explain some concept again if it’s not clear. Feel free to chat with me on Twitter. Thanks for reading!