
Overview of tokenization algorithms in NLP
Introduction to tokenization methods, including subword, BPE, WordPiece and SentencePiece


This article is an overview of tokenization algorithms, ranging from word level, character level and subword level tokenization, with emphasis on BPE, Unigram LM, WordPiece and SentencePiece. It is meant to be readable by both experts and beginners alike. If any concept or explanation is unclear, please contact me and I will be happy to clarify whatever is needed.
What is tokenization?
Tokenization is one of the first steps in NLP, and it’s the task of splitting a sequence of text into units with semantic meaning. These units are called tokens, and the difficulty in tokenization lies on how to get the ideal split so that all the tokens in the text have the correct meaning, and there are no left out tokens.
In most languages, text is composed of words divided by whitespace, where individual words have a semantic meaning. We will see later what happens with languages that use symbols, where a symbols has a much more complex meaning than a word. For now we can work with English. As an example:
- Raw text: I ate a burger, and it was good.
- Tokenized text: [’I’, ’ate’, ’a’, ’burger’, ‘,’, ‘and’, ’it’, ’was’, ’good’, ‘.’]
‘Burger’ is a type of food, ‘and’ is a conjunction, ‘good’ is a positive adjective, and so on. By tokenizing this way, each element has a meaning, and by joining all the meanings of each token we can understand the meaning of the whole sentence. The punctuation marks get their own tokens as well, the comma to separate clauses and the period to signal the end of the sentence. Here is an alternate tokenization:
- Tokenized text: [’I ate’, ’a’, ’bur’, ‘ger’, ‘an’, ‘d it’, ’wa’, ‘s good’, ‘.’]
For the multiword unit ‘I ate’, we can just add the meanings of ‘I’ and ‘ate’, and for the subword units ‘bur’ and ‘ger’, they have no meaning separately but by joining them we arrive at the familiar word and we can understand what it means.
But what do we do with ‘d it’? What meaning does this have? As humans and speakers of English, we can deduce that ‘it’ is a pronoun, and the letter ‘d’ belongs to a previous word. But following this tokenization, the previous word ‘an’ already has a meaning in English, the article ‘an’ very different from ‘and’. How to deal with this? You might be thinking: stick with words, and give punctuations their own tokens. This is the most common way of tokenizing, called word level tokenization.
Word level tokenization
It consists only of splitting a sentence by the whitespace and punctuation marks. There are plenty of libraries in Python that do this, including NLTK, SpaCy, Keras, Gensim or you can do a custom Regex.
Splitting on whitespace can also split an element which should be regarded as a single token, for example, New York. This is problematic and mostly the case with names, borrowed foreign phrases, and compounds that are sometimes written as multiple words.
What about words like ‘don’t’, or contractions like ‘John’s’? Is it better to obtain the token ‘don’t’ or ‘do’ and ‘n’t’? What if there is a typo in the text, and burger turns into ‘birger’? We as humans can see that it was a typo, replace the word with ‘burger’ and continue, but machines can’t. Should the typo affect the complete NLP pipeline?
Another drawback of word level tokenization is the huge vocabulary size it creates. Each token is saved into a token vocabulary, and if the vocabulary is built with all the unique words found in all the input text, it creates a huge vocabulary, which produces memory and performance problems later on. A current state-of-the-art deep learning architecture, Transformer XL, has a vocabulary size of 267,735. To solve the problem of the big vocabulary size, we can think of creating tokens with characters instead of words, which is called character level tokenization.
Character level tokenization
First introduced by Karpathy in 2015, instead of splitting a text into words, the splitting is done into characters, for example, smarter becomes s-m-a-r-t-e-r. The vocabulary size is dramatically reduced to the number of characters in the language, 26 for English plus the special characters. Misspellings or rare words are handled better because they are broken down into characters and these characters are already known in the vocabulary.
Tokenizing sequences at the character level has shown some impressive results. Radford et al. (2017) from OpenAI showed that character level models can capture the semantic properties of text. Kalchbrenner et al. (2016) from Deepmind and Leet et al. (2017) both demonstrated translation at the character level. These are particularly impressive results as the task of translation captures the semantic understanding of the underlying text.
Reducing the vocabulary size has a tradeoff with the sequence length. Now, each word being splitted into all its characters, the tokenized sequence is much longer than the initial text. The word ‘smarter’ is transformed into 7 different tokens. Additionally, the main goal of tokenization is not achieved, because characters, at least in English, have no semantic meaning. Only when joining characters together do they acquire a meaning. As an in-betweener between word and character tokenization, subword tokenization produces subword units, smaller than words but bigger than just characters.
Subword level tokenization
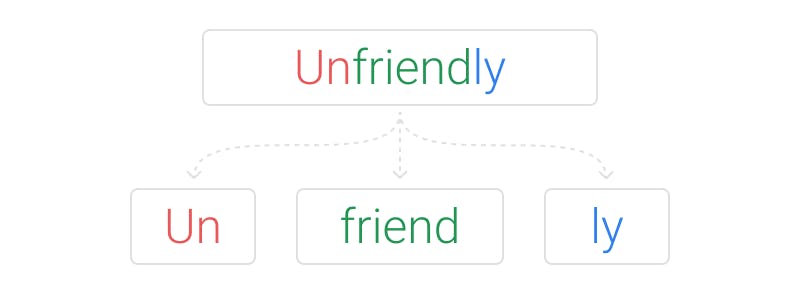
Example of subword tokenization
Subword level tokenization doesn’t transform most common words, and decomposes rare words in meaningful subword units. If ‘unfriendly’ was labelled as a rare word, it would be decomposed into ‘un-friend-ly’ which are all meaningful units, ‘un’ meaning opposite, ‘friend’ is a noun, and ‘ly’ turns it into an adverb. The challenge here is how to make that segmentation, how do we get ‘un-friend-ly’ and not ‘unfr-ien-dly’.
As of 2020, the state-of-the-art deep learning architectures, based on Transformers, use subword level tokenization. BERT makes the following tokenization for this example:
- Raw text: I have a new GPU.
- Tokenized text: [’i’, ’have’, ’a’, ’new’, ’gp’, ’##u’, ’.’]
Words present in the vocabulary are tokenized as words themselves, but ‘GPU’ is not found in the vocabulary and is treated as a rare word. Following an algorithm it is decided that it is segmented into ‘gp-u’. The ## before ‘u’ are to show that this subword belongs to the same word as the previous subword. BPE, Unigram LM, WordPiece and SentencePiece are the most common subword tokenization algorithms. They will be explained briefly because this is an introductory post, if you are interested in deeper descriptions, let me know and I will do more detailed posts for each of them.
BPE
Introduced by Sennrich et al. in 2015, it merges the most frequently occurring character or character sequences iteratively. This is roughly how the algorithm works:
- Get a large enough corpus.
- Define a desired subword vocabulary size.
- Split word to sequence of characters and append a special token showing the beginning-of-word or end-of-word affix/suffix respectively.
- Calculate pairs of sequences in the text and their frequencies. For example, (’t’, ’h’) has frequency X, (’h’, ’e’) has frequency Y.
- Generate a new subword according to the pairs of sequences that occurs most frequently. For example, if (’t’, ’h’) has the highest frequency in the set of pairs, the new subword unit would become ’th’.
- Repeat from step 3 until reaching subword vocabulary size (defined in step 2) or the next highest frequency pair is 1. Following the example, (’t’, ’h’) would be replaced by ’th’ in the corpus, the pairs calculated again, the most frequent pair obtained again, and merged again.
BPE is a greedy and deterministic algorithm and can not provide multiple segmentations. That is, for a given text, the tokenized text is always the same. A more detailed explanation of how BPE works will be detailed in a later article, or you can also find it in many other articles.
Unigram LM
Unigram language modelling (Kudo, 2018) is based on the assumption that all subword occurrences are independent and therefore subword sequences are produced by the product of subword occurrence probabilities. These are the steps of the algorithm:
- Get a large enough corpus.
- Define a desired subword vocabulary size.
- Optimize the probability of word occurrence by giving a word sequence.
- Compute the loss of each subword.
- Sort the symbol by loss and keep top X % of word (X=80% for example). To avoid out of vocabulary instances, character level is recommended to be included as a subset of subwords.
- Repeat step 3–5 until reaching the subword vocabulary size (defined in step 2) or there are no changes (step 5)
Kudo argues that the unigram LM model is more flexible than BPE because it is based on a probabilistic LM and can output multiple segmentations with their probabilities. Instead of starting with a group of base symbols and learning merges with some rule, like BPE or WordPiece, it starts from a large vocabulary (for instance, all pretokenized words and the most common substrings) that it reduces progressively.
WordPiece
WordPiece (Schuster and Nakajima, 2012) was initially used to solve Japanese and Korean voice problem, and is currently known for being used in BERT, but the precise tokenization algorithm and/or code has not been made public. It is similar to BPE in many ways, except that it forms a new subword based on likelihood, not on the next highest frequency pair. These are the steps of the algorithm:
- Get a large enough corpus.
- Define a desired subword vocabulary size.
- Split word to sequence of characters.
- Initialize the vocabulary with all the characters in the text.
- Build a language model based on the vocabulary.
- Generate a new subword unit by combining two units out of the current vocabulary to increment the vocabulary by one. Choose the new subword unit out of all the possibilities that increases the likelihood on the training data the most when added to the model.
- Repeat step 5 until reaching subword vocabulary size (defined in step 2) or the likelihood increase falls below a certain threshold.
SentencePiece
All the tokenization methods so far required some form of pretokenization, which constitutes a problem because not all languages use spaces to separate words, or some languages are made of symbols. SentencePiece is equipped to accept pretokenization for specific languages. You can find the open source software in Github. For example, XLM uses SentencePiece and adds specific pretokenizers for Chinese, Japanese and Thai.
SentencePiece is conceptually similar to BPE, but it does not use the greedy encoding strategy, achieving higher quality tokenization. SentencePiece sees ambiguity in character grouping as a source of regularization for the model during training, which makes training much slower because there are more parameters to optimize for and discouraged Google from using it in BERT, opting for WordPiece instead.
Conclusion
Historically, tokenization methods have evolved from word to character, and lately subword level. This is a quick overview of tokenization methods, I hope the text is readable and understandable. Follow me on Twitter for more NLP information, or ask me any questions there :)