
How to learn deep learning by reading papers
Create a system in order to be up to date with deep learning research


Deep learning is moving so fast, that the only way to keep up is by reading directly from the people who publish these new findings. If you’re a technical person and want to learn about deep learning in 2021, you need to read papers.
Formal education will only get you so far. Unfortunately, universities in general are slow to incorporate new material into their curriculums and only a few years ago did they start to teach deep learning. This is the case in Europe, I acknowledge it might be different in the US.
Deep learning in university
Under the fancy names of AI and Deep learning, most of the courses squeeze classical machine learning networks, neural networks, CNNs, RNNs, LSTMs and applications such as car line detection under just one semester.
If that is your first contact with machine learning, at the end of it you will only know the general idea of the networks, and some code snippets for your assignments. You can’t learn ML in one semester.
And because the material is so new and the people who know about it so few, most of the courses are poorly designed, use fancy names to attract people, but only teach them basic things. Unless you attend a university with a complete and specialized ML curriculum, you can’t count on university alone to learn deep learning.
Deep learning in books
The next option is books, written by AI researchers. The deep learning book by Goodfellow and other renowned AI researchers is a very thorough book for foundation knowledge. You can read individual chapters online for free, or pay forthe whole book.
The problem with books is that since they take so much time to make and the field moves so fast, by the time it’s published some things might be obsolete already. You can use books for foundation knowledge but if you don’t want your knowledge to become obsolete, you need to keep up with current research.
Deep learning in online courses
There are countless machine learning and deep learning online courses in Coursera, EdX, and many other platforms. Like with books, online courses need a lot of time to record, edit and publish the videos and the content. You can use them for the solid foundation of your knowledge and perhaps to practice coding, but the deep learning certification I did in Coursera in 2018 hasn’t changed in 3 years and the field certainly has.
Deep learning with university videos
This is certainly a fruitful approach. Many US universities like post their lectures online, and some of them give access to their assignments. These universities are the only ones offering updated education in deep learning, in a structured format and with people who know what they’re talking about. Michigan’s Deep learning for computer vision is quite popular for example. Stanford also publishes some of their lectures after the semester ends, so watch out for them since they’re quite up to date.
They are not entirely up to date, since courses take preparation time too. By the time the lecturers start preparing the material until the semester begins and ends, a whole year might have passed. And in that year many new things will have been published. Still, it’s a very good approach to learn about specifics areas of deep learning such as computer vision, NLP, translation, speech or whatever interests you up to a year before you watch the videos. For the last year, you will have to read papers.
Deep learning with papers
I recommend you use structured methods such as the ones I mentioned before to build the solid blocks of your deep learning knowledge. Once you have learnt the general notions of deep learning, I take the guess you have made it as far as around 2016. If you have watched the US university videos, maybe until 2018. I assume you have learnt about CNNs, RNNs/LSTMs, some computer vision and NLP.
If you want to know about newer terms like Transformers, BERT, pre-trained models, transfer learning, bias, ethics in AI, zero-short learning, neural translation, GANs, reinforcement learning, multimodal models, and many other terms you will have to turn to papers since these terms haven’t made it to online courses, books and university lectures yet.
Reading papers
arXiv is an archive for papers, where deep learning researchers upload their papers. The number of papers in arXiv has increased steadily over the years. Generally fields have stalled or slightly increased, but Mathematics and Computer Science (CS) have exploded. These are typically the sections where machine learning or deep learning falls into.
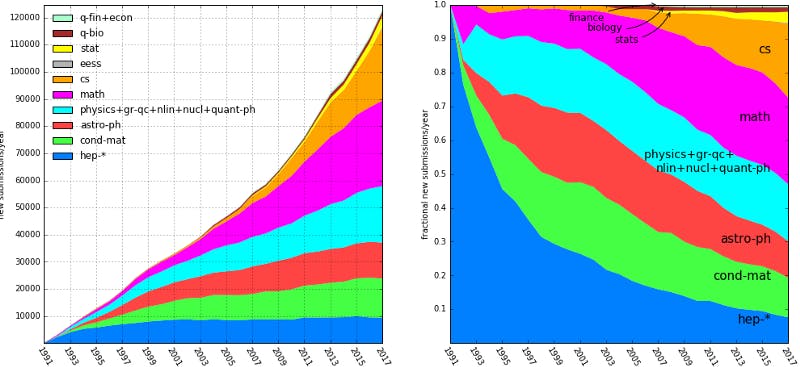
Cumulative papers in arXiv based on category
Machine learning was a branch of mathematics until training deep neural networks became possible, and after then it’s known as Deep learning. Computer vision had its golden years with ImageNet around 2013, in 2015 NLP started its own era with LSTMs and it is still going strong with the advancements of recent years, Transformers, pre-trained models and other more hidden research on datasets and bias.
As of 2018, there were around 100 new ML papers every day, much higher than Moore’s law, which states that the amount doubles every two years. And the Transformer model was introduced in 2018 which was a big boom, so I estimate the number of new Arxiv papers has either increased or at least stayed constant.
It is worth noting that Arxiv papers are just prepublished papers, some of them are then published in conferences and journals but most aren’t. However, many non-published papers have high value and are worth considering.
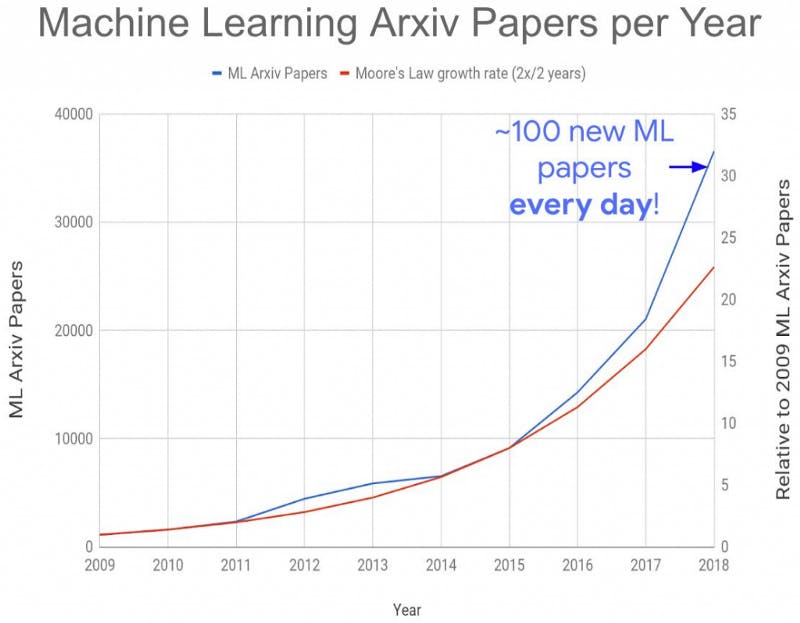
Cumulative number of ML arXiv papers per year (arxiv)
Looking at machine learning specifically, the number of publications is accelerating. I was tempted to write that the research is accelerating, but the number of publication isn’t correlated with the advance in the field unfortunately.
If you have followed the publications on ML in the past years, you will have noticed the more and more papers are published. You might have feel overwhelmed as to how to separate the relevant ones from the more specific ones. This will have been even more difficult if you are not in academia and keeping up with research isn’t your job.
Andrej Karpathy, one of the leaders in deep learning, recently talked about how difficult it is to keep up with deep learning research, since there are so many papers.
I don’t have a perfect method but in this post I would like to share how I keep up with the relevant papers in deep learning and the subfields I’m interested in: NLP, specifically sarcasm detection and some computer vision.
1. Filtering relevant papers
Anyone trying to keep up with the current research has surely asked themselves:
There are so many papers.
Which ones do I read?
How do I find the important papers?
At this high rate of new papers, we can forget about manually inspecting and filtering. Unfortunately arXiv doesn’t have any ranking systems, so it’s difficult to find interesting papers by going to the page directly. I will detail the sources from which I obtain a list of potential papers.
1.1. Twitter
I have a list of deep learning people who regularly post links to new papers that they find relevant. By following different research fields, you will get a pool of interesting papers in each field. Some of the people I follow are:
- Google AI who post research done by Google in all areas of deep learning, usually outside of arXiv. Can include computer vision, NLP, reinforcement learning, GANs.
- General ML/DL researchers: Sara Hooker, hardmaru, omarsar0
- NLP researchers: Arkaitz Zubiaga, Jasmijn Bastings, Rachael Tatman, Mikel Artetxe
- Computer vision: Andrej Karpathy
Many of this people will retweet from other people, so you can find other sources through them. I want to make a special mention to hardmaru and omarsar0 who regularly post a link to an interesting paper and a brief summary, as well as many resources to learn deepl earning concepts. Also a mention to Rachael Tatman who holds regular paper readings where she streams while she reads a paper and she explains many concepts in the meantime.
If there is a specific area of deep learning you are interested in, you can search researchers or practitioners on Twitter, and you will have a regular influx of new content for you.
1.2. ArXiv sanity preserver webpage
ArXiv sanity preserver is a website built by Karpathy with the aim to preserve sanity by filtering the relevant papers. You can rank based on different criteria: most recent, top recent, top hype (number of retweets), and another features available if you make an account to save your preferences.
I personally like the top hype section where you can see the most mentioned papers on Twitter in the last day, week or month. The idea is that relevant or influential papers will be circulated and talked about.
For example, at the time of writing BERT (published in 2018) is in the top hype list with high engagement on Twitter. We can see that was an important paper. If you see a 2–3 year old paper from your field of interest in the list, I would certainly take a look at it.
Despite the usefulness of this website, Karpathy himself has said the number of relevant papers filtered in this website is too high to keep up with, so more filtering might be necessary.
1.3. Papers with code webpage
This is another way you can find trending research, in this case all the papers in this website provide code to their paper, which can be really useful if you want to replicate it or take a deeper look.
You can find general trending papers, or organized by sections: computer vision, NLP, medical, speech, etc. You can also browse by methods used in the deep learning models.
1.4. Awesome Github repositories
In Github, awesome repositories are curated lists of resources, you can find information about almost every topic. Data science, machine learning and deep learning have their own awesome repositories with code, tutorials, books and papers. Here you can find a curated list of deep learning papers, although it hasn’t been updated in a couple of years.
For more specific list of deep learning subfields, you can search for ‘github awesome computer vision medical’ for example for your specific usecase.
1.5. My own list of papers :)
This is a bit of self-promotion, but I also have my own list of relevant papers separated by topic and ordered chronologically, labeled with tags. For example you can find an NLP dataset for sarcasm detection, which you can find by looking the hashtags #datasets and #sarcasm-detection. I mostly collect NLP papers but not exclusively, and I include many older, fundamental papers that are the basics for current research.
If you find it interesting, make sure to star the repository :)
1.6. But what if I am just starting and these papers are too difficult?
This is a real problem. If you’ve never read a research paper and try to read any current paper, most probably you will understand next to nothing. And that is because research is cumulative, each paper references many older papers, which in turn are based on previous papers.
My journey with NLP research
When I started reading NLP papers, in the introduction the authors mentioned they were using some architecture introduced by some people. I wasn’t familiar with it so I found the paper and started reading it. This architecture was referencing something I also didn’t know, so I looked that up and started reading that other paper.
I wanted to read one paper and in the end I had a stack of 15 papers that were recursively referencing others.
So my advice is, don’t feel bad for not understanding most of the concepts that are mentioned in papers. It will probably be referenced, so find that paper and try to understand that one first.
You will have to recursively go back in time until the foundation papers but once you do and start understanding the basics, you will build the blocks of your knowledge and have a strong understanding of the papers you read.
Depending on your previous knowledge, this might take some time. But if you want to read and understand papers, you need to understand the references.
Additionally, this amazing deep learning papers roadmap repository contains chronologically ordered papers from more foundational and generic to more specific. You can use this too to guide your learning.
2. Organizing paper reading
If you have followed the steps of part 1, you will have many papers in your list. Reading papers is an activity that requires focus for at least one hour, so unless you’re an academic and can read papers every day, you will have to find time in your schedule to read them.
You can try different strategies, one that works for me is to read 3 papers a week, after work during the workweek. In the previous Sunday I choose which 3 I will read next and allocate time in my calendar. Sometimes other things come up but this system works very well for me.
3. Reading the papers
You have your list of papers you want to read, either from foundation papers to more current ones or from the first few resources I mentioned. I recommend you focus on one topic at a time. If you are interested in speech, focus your time on speech until you feel confident of your knowledge before moving to another subfield.
But once you have chosen the paper you want to read, how to actually do it?
2.1. Analog vs. digital
This is a personal preference, some people like to read pdfs in their computer while others prefer to print it and make notes on paper.
2.2. Get the general idea of the paper first
Before you start reading the details, get the general idea of what the paper introduces. Is it a dataset, a model, a system? What is it based on, how does it work in general terms?
If you understand that, then you can go deep in the methodology. Otherwise, I recommend reading the reference first.
2.3. Make notes
Unless you have an amazing memory, you will forget many of the things you read and it would be a waste of time after spending so much time on it. So I recommend that you save your learnings like I did with my papers repository.
If you prefer saving your notes in a notebook, that’s fine just make sure they are easily searchable and you can jump fast from one to the other when one paper references another.
Whatever medium you choose, I think it’s a very good idea to make notes of what you understand, and save it somewhere. Feel free to copy the tempate of my repository and make your own list.
4. Keeping up with new papers
Reading papers is a task that never ends, so how to keep up with new papers?
I follow many researchers on Twitter so if they talk about a paper and I’m interested, I add it to my list. Then, I have a weekly reminder every Sunday to check arXiv sanity preserver and papers with code if there are any papers I want to read. If so, I add them to the list. And finally I allocate the 3 papers to read the following week.
Conclusion
Deep learning is moving at faster and faster rate, and although it’s inevitable to miss out on some things, I want to be somewhat up to date on the research in my job field and I know many people do too.
I hope this post helped you create a system to keep up with this chaotic rate of new papers, feel free to star my repo on Github to see updates on new papers I read, follow me on Twitter or send me a message if you have any questions :)
Thanks for reading!