

Analysis of contextual embedding similarity for similar sentences
Given similar sentences, how similar are their contextual embeddings? Let’s find out


Embeddings are a key part of modern NLP, they encode the meaning of words or other linguistic units into vectors of numbers. The embedding of a specific word might seem random, but the idea is that similar words have similar embeddings, and opposite words have opposite embeddings.
For example, imagine this is king’s embedding: [2, 3, 1, 0, 5]. Prince’s embedding might be [1, 3, 1, 0, 4], the difference between the vectors is just 2, which means these 2 words are linguistically very close. Queen’s embedding might be [2, 3, -1, -10, 0] where some similarity is mantained (king and queen are part of the monarchy group of words), but other parts are opposite. In this case the distance between the embeddings is much bigger.
This is the classical way of embeddings, just with words. We can experiment with word embedding algorithms (word2vec, GloVe, FastText) and check how different the embeddings are for synonyms, antonyms and unrelated words.
In this post I go a bit further and explore the same concept but for contextual embeddings. How do embeddings change for similar sentences?
Contextual embeddings
Contextual embeddings also assign embeddings to words, but they take into accout the context, the surrounding words. The word king has a different embedding in these 2 sentences:
- The king went into his castle after the deer hunt
- Last Halloween I dressed up as a king
There are mainly three types of contextual embeddings. As a short description, this is how each of them form embeddings:
- ELMo: released in 2018, was the first type of contextual embeddings, they are obtained by using a bidirectional recurrent neural network and simply concatenates left and right context at the last layer of their model. Sentences are processed sequentially.
- Flair: released in 2019, they are trained without any explicit notion of words and thus fundamentally model words as sequences of characters. Sentences are processed sequentially.
- BERT: released in late 2018, is a newer version of ELMo, they condition on both left and right context in all layers of their Transformer model. Sentences are processed as a bag of words.
To obtain a sentence or document embedding, a kind of average of all the contextual embeddings is done. You can read more about these embeddings and document embeddings in the Flair repo docs.
Experiments
So how do contextual embeddings change for different sentences? If I give two ‘opposite’ sentences, their embeddings should be opposite too, right? But what constitutes an opposite sentence?
I built a website to play around: [share.streamlit.io/anebz/eu-sim/similarity.py](share.streamlit.io/anebz/eu-sim/similarity.py feel free to change the language and the sentences. You can find the code for the Python code and Streamlit frontend in the Github repo here. You can star the repository if you want to receive updates about new features.
I set this sentence as the main sentence
The doctor invited the patient for lunch
In the sample sentences I tried to capture different events:
- negation (didn’t invite)
- Subject and object swap (the patient invited the doctor)
- Subject synonym (surgeon instead of doctor)
- Object synonym (lunch instead of meal)
- Similar action (go out for tea instead of invite for lunch)
- Nonsensical permutation of the main sentence words
- A random sentence in the same language
- A random sentence in another language
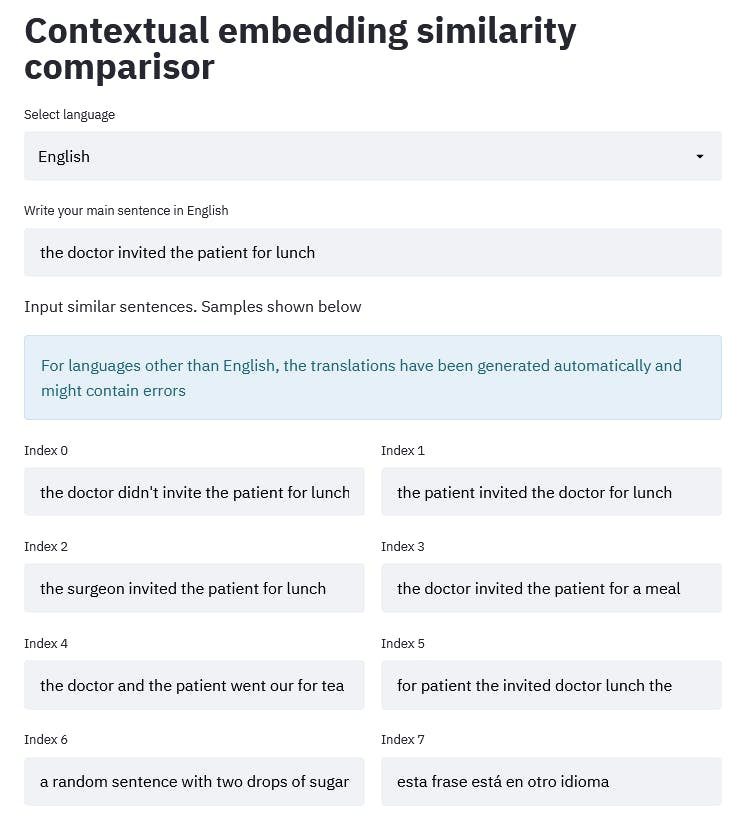
Screenshot from the website
I tried the classic word embeddings and the 3 contextual embeddings, and these are the similarities of each similar sentence with the main sentence:
Similarity results for sample sentences
Some interesting conclusions:
- In my ignorant opinion, linguistically speaking, someone doing something is opposite to someone not doing something. Meaning wise, it is the opposite. Yet it seems that the embeddings are very very similar, over 90% similarity in all 4 cases. This might be because in all the possible ways we can join words to form a sentence, these 2 sentences are talking about the same specific thing and the contrast is only a small part compared to how similar they are.
- The embedding similarity is even higher (over 97%) for subject-object swapping.
- Subject and object synonyms also yield very high embedding similarities (over 95%) which is logical.
- Index 4 is a similar action but with different words, making the similarity slightly lower, 80% or above.
- Indexes 1 and 5 contain the same words as the main sentence but changed in order, with a different meaning. Unsurprisingly, word embeddings are exactly the same as in the main sentence.
- Index 5 is nonsensical yet contextual embeddings are very similar to the ones from the main sentence.
- For random sentences, the similarities go lower with the lowest similarity being for a random sentence in another language.
- Yet BERT yield very high similarity even for random sentences in other languages. The random English sentence has a similarity of 76% while the random Spanish one has 80%. It remains a mystery what kind of sentence can generate a very different BERT embedding.
Open questions
I did this research as part of a university assignment and I asked myself some questions, which now I write here as open questions for the readers. I made some experiments and wrote my findings in the talk slides. I recommend trying out the experiments in the website yourself before looking up my conclusions!
- Does word order matter in contextual embeddings?
- What is the impact of lexical similarity? (Sentences containing the same words)
- What is the impact of synonyms?
- What is the impact of out of vocabulary words? (Words that the embeddings don’t recognize: misspellings, foreign words)
The website is free to use, you can do as many experiments as you want and I added many languages, you can check how embeddings change and adapt to different languages. Feel free to check the source code on Github, start the repository and chat with me on Twitter if you have any questions, interesting findings or you just want to connect :)
Thanks for reading!